Recherche
Espace privatif du doctorat



Dans cette thèse, nous abordons les défis de la rareté des annotations et la fusion de données hétérogènes tels que les nuages de points 3D et images 2D. D'abord, nous adoptons une stratégie de conduite de course de bout en bout où un réseau de neurones est entraîné pour directement traduire l'entrée capteur (image caméra) en contrôles-commandes, ce qui rend cette approche indépendante des annotations dans le domaine visuel. Nous utilisons l'apprentissage par renforcement profond où l'algorithme apprend de la récompense, obtenue par interaction avec un simulateur réaliste. Nous proposons de nouvelles stratégies d'entraînement et fonctions de récompense pour une meilleure conduite et une convergence plus rapide. Cependant, le temps d'apprentissage reste élevé. C'est pourquoi nous nous concentrons sur la perception dans le reste de cette thèse pour étudier la fusion de nuage de points et d'images. Nous proposons deux méthodes différentes pour la fusion 2D-3D. Premièrement, nous projetons des nuages de points LiDAR 3D dans l'espace image 2D, résultant en des cartes de profondeur très peu denses. Nous proposons une nouvelle architecture encodeur-décodeur pour fusionner les informations de l'image et la profondeur pour la tâche de complétion de carte de profondeur, ainsi améliorant la résolution du nuage de points au niveau de résolution de l'image. Deuxièmement, nous fusionnons directement dans l'espace 3D pour éviter la perte d'informations par projection. Pour cela, nous calculons les caractéristiques d'image issues de plusieurs vues avec un CNN 2D, puis nous les élevons dans un nuage de points 3D global pour les fusionner avec l'information 3D. Par la suite, ce nuage de point enrichi avec des informations d'image est pris en entrée par un réseau basé sur points pour prédire les étiquettes sémantiques 3D. Sur la base de ce travail, nous introduisons la nouvelle tâche plus difficile d'adaptation de domaine non supervisée intermodale, où on a accès à des données multimodales dans une base de données source annotée et une base cible non annotée. Nous proposons une méthode d'apprentissage intermodal 2D-3D via une imitation mutuelle entre les réseaux d'images et de nuages de points pour aborder l'écart de domaine source-cible. Nous montrons en outre que notre méthode est complémentaire à la technique unimodale existante de pseudo-étiquetage.
In this thesis, we address the challenges of label scarcity and fusion of heterogeneous 3D point clouds and 2D images. We adopt the strategy of end-to-end race driving where a neural network is trained to directly map sensor input (camera image) to control output, which makes this strategy independent from annotations in the visual domain. We employ deep reinforcement learning where the algorithm learns from reward by interaction with a realistic simulator. We propose new training strategies and reward functions for better driving and faster convergence. However, training time is still very long which is why we focus on perception to study point cloud and image fusion in the remainder of this thesis. We propose two different methods for 2D-3D fusion. First, we project 3D LiDAR point clouds into 2D image space, resulting in sparse depth maps. We propose a novel encoder-decoder architecture to fuse dense RGB and sparse depth for the task of depth completion that enhances point cloud resolution to image level. Second, we fuse directly in 3D space to prevent information loss through projection. Therefore, we compute image features with a 2D CNN of multiple views and then lift them all to a global 3D point cloud for fusion, followed by a point-based network to predict 3D semantic labels. Building on this work, we introduce the more difficult novel task of cross-modal unsupervised domain adaptation, where one is provided with multi-modal data in a labeled source and an unlabeled target dataset. We propose to perform 2D-3D cross-modal learning via mutual mimicking between image and point cloud networks to address the source-target domain shift. We further showcase that our method is complementary to the existing uni-modal technique of pseudo-labeling.
Titre anglais : 2D-3D scene understanding for autonomous driving
Date de soutenance : vendredi 26 juin 2020 à 14h00
Adresse de soutenance : Inria, 2 Rue Simone IFF, 75012 Paris - Jacques-Louis Lions
Directeurs de thèse : Fawzi NASHASHIBI, Raoul DE CHARETTE







Ecole
240 ans de recherche et de formation
Vidéo : 240ans de recherche…
> En savoir +

Formation
Samuel Forest, élu membre de l’Académie des…
Samuel Forest lors de sa réception à…
> En savoir +

Formation
Mines Paris plébiscitée par ses étudiantes
Mines Paris - PSL, une école qui répond…
> En savoir +

Formation
Corentin Gombert, prix de thèse de l’ARIMHE
Corentin Gombert, doctorant au CGS Mines Paris - PSL, lors de…
> En savoir +
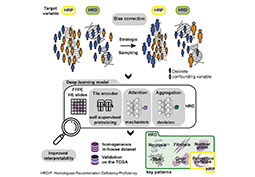
Formation
L'analyse d'images pour une médecine personnalisée du…
L'interprétation des prédictions des…
> En savoir +

Formation
Femmes de science
Chercheuses confirmées, doctorantes, élèves ou alumni,…
> En savoir +

Voir l'agenda des formations et autres actualités

Consultez régulièrement les offres de formation
